本文共 5566 字,大约阅读时间需要 18 分钟。
1.mongoDB简介
1.NoSQL数据库
数据库:进行高效的、有规则的进行数据持久化存储的软件
NoSQL数据库:Not only sql,指代非关系型数据库
优点:高可扩展性、分布式计算、低成本、灵活架构、半结构化数据、简化关联关系
缺点:没有标准化、有限查询、不直观
常见NoSQL数据库
列存储:Hbase、Cassandra、Hypertable
文档存储:MongoDB、CouchDB
k-v存储:TokyoCabinet、BerkeleyDB、MemcacheDB、redis
对象存储:Neo4J、Versant
Xml数据库:BerkeleyDB、BaseX
注:加粗的为常用的数据库
2.MongoDB概述
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
优点:
C++编写的运行稳定性能高的数据
模式自由
面向集合
完整索引支持
复制和高可用性
3.Mongodb术语解释
database--database:数据库
table – collection:数据库表 – 集合
row – document:数据记录 – 文档
column – field:数据字段 – 域
index – index :索引 – 索引
table-join – None:表连接~
primary key – primary key :主键
4.MongoDB基本语法——数据类型
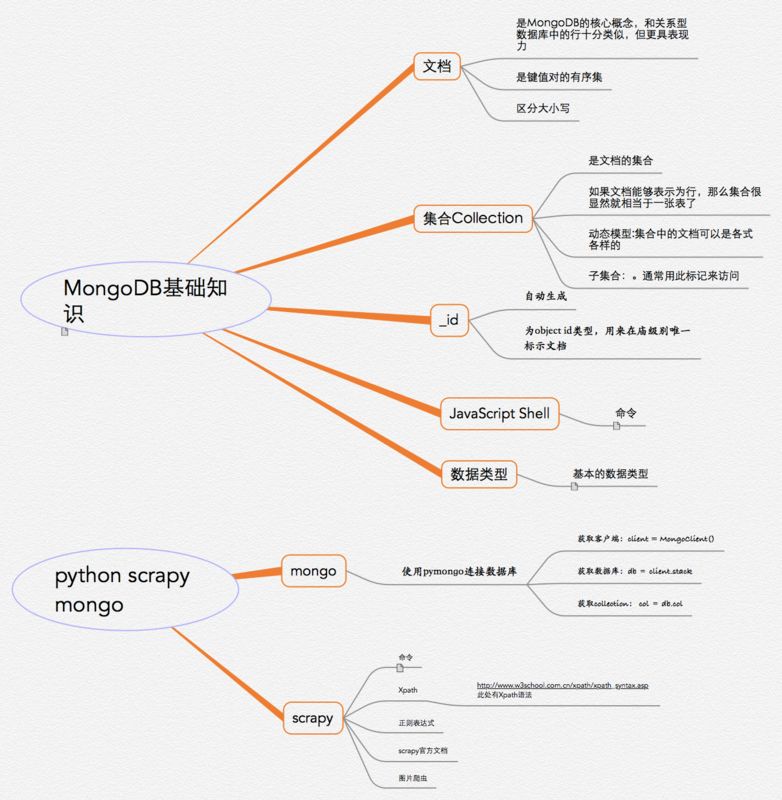
集合就是关系型书库中的表
文档对应关系型数据库中的行
文档:就是一个JSON对象,由KEY=VALUE键值对构成
{“name”:”admin”, “gender”:”男”} 集合:存储多个文档,结构不固定
{“name”:”admin”, “gender”:”男”} {“name”:”manager”, “age”:23} {“name”:”manager”, “phone”:”16868686868”} 数据库:存储多个集合
服务器:一个服务器中可以包含多个数据库
ObjectID:文档id
String:字符串
Boolean:布尔值
Integer:整数
Double:浮点数
Arrays:数组或者列表
Object:嵌入的文档
Null:空值
Timestamp:时间戳
Date:日期时间
2.MySQL的安装
回顾一下MySQL在ubuntu的安装
在终端输入命令
sudo apt-get install mysql-server sudo apt-get install mysql-client sudo apt-get install libmysqlclient-dev #安装过程中会提示设置密码什么的,注意设置了不要忘了
安装完毕后输入以下命令检测是否安装成功
sudo netstat -tap | grep mysql

登陆mysql数据库可以通过如下命令:
mysql -u root -p
-u 表示选择登陆的用户名, -p 表示登陆的用户密码,上面命令输入之后会提示输入密码,此时输入密码就可以登录到mysql。

3.Mongodb下载安装
官方网站【https://www.mongodb.com/】
注意:偶数为稳定版,如1.6,奇数为开发版,如1.7
1.Windows下Mongodb安装

我这里用的是zip安装,安装完毕后,

当前所在磁盘目录下创建data文件夹 
data文件夹中创建db文件夹和log文件夹
在运行窗口输入命令启动数据库
mongod --dbpath d:/data/db
启动mongoDB数据库
打开一个新的窗口输入命令`mongo`,用于数据库操作

打开一个新的窗口,用于数据库操作
2.Linux下Mongodb安装
MongoDB安装很简单,无需下载源文件,可以直接用apt-get命令进行安装。
1 . 打开终端,输入以下命令:
sudo apt-get install mongodb
2 . 安装完成后,在终端输入以下命令查看MongoDB版本:
mongo -version

在终端输入命令
sudo mongo

3.安装pymongo
PyMongo是Mongodb的Python接口开发包,是使用python和Mongodb的推荐方式。
用Python操作MongoDB需要通过PyMongo,输入命令安装
pip install pymongo 默认安装 pip install pymongo==2.8 安装指定版本 pip install –upgrade pymongo 升级PyMongo


4.Mongodb基本使用
1.基本操作
mongoDB将数据存储为一个文档
数据由 key=value 的键值对的形式组成
数据的操作:增删改查
nosql三元素:数据库 – 集合 – 文档 [--域]
2.基本语法
数据库操作
db:查看当前指向的数据库
show dbs:查看当前所有的数据库
use :指向一个数据库
Use数据库不会创建数据库,如果操作数据会自动创建数据库db.dropDatabase():删除当前指向的数据库
集合操作
show collections:查看当前数据库所有集合
db.createCollection([, options]):创建一个集合
db..drop():删除指定的集合
show collections 查看当前库中所有的集合,后面的collections不要加括号 db.createCollection(name, [optinos]) 创建一个名称为name的集合,后面的options表示创建的附带选项 db.createCollection(“emp”):创建一个名称为emp的名称的集合 db.createCollection(“dept”, {“capped”: true, size: 5}):capped默认false 表示不设置上限,true表示设置上限需要设置size参数~表示达到上限时会将之前的数据覆盖 增加数据
语法:
db..insert(文档)集合可以是原来存在的,可以是不存在的
文档:就是JSON格式表示的数据
简单查询:
db..find()查询指定集合的数据
db.student.insert({ name:”jerry”, gender:”男”}) db.student.insert({ _id:”1”, name:”tom”, gender:”女”, age:18}) 更新数据
语法:
db..update(,,[multi:])指定属性更新:
$opration
multi:默认false更新符合条件第一条,设置true全集合更新
#更新符合条件的文档 db.student.update({name:”tom”}, {name:”jerry”}) #更新符合条件的文档中符合条件的域 db.student.update({name:”tom”}, { $set:{name:”jerry”}}) #更新符合条件的多行文档及对应的域 db.student.update({}, { $set:{name:”donghua”}}, {multi:true}) 保存数据
语法:
db..save(文档)特征:[ _id ]如果数据不存在就添加,如果数据存在修改
删除数据
语法:
db..remove(, {justone:})参数query:删除文档的条件
参数justOne:设置为true或者1,删除一条;默认false删除多条
查询数据
基本查询
find([{文档条件}]):全集合查询
findOne([{文档条件}]):查询第一个
pretty():将查询结果格式化展示
比较运算符
默认判断,无运算符 $lt:little~小于 < $lte:little or equals~小于等于 <= $gt:granter~大于 > $gte:granter or equals~大于等于 >= #查询名称为jerry的学生 db.student.find({name:”jerry”}) #查询年龄已经适婚年龄的学员 db.student.find({age:{$gte:20}}) 逻辑运算符
逻辑与:并且运算,默认操作,无运算符
逻辑或:或者运算,
$or
#查询年龄已经适婚年龄并且性别为女的学员 db.student.find({age:{ $gte:20}, gender:”女”}) #查询年龄大于18或者性别为男的学员 db.student.find({ $or:[{age:{ $gt:18}, {gender:”女”}]}) 范围运算符
$in:判断指定条件是否包含在某个范围内$nin:判断指定条件是否不包含在某个范围内
#查询年龄在18或者20的学员 db.student.find({ age: {$in:[18,20]}}) #查询年龄不是18 的学员 db.student.find({ age: {$nin : [20]}}) 限制查询条数
.limit(count)
排序
.sort({字段:1/-1, ...}) db.student.find().sort({name:1}) 1.表示升序排列 -1表示降序排列,可以指定多个字段
去重
db. <集合名称> .distinct(“去重域名称”, {条件}) 查询数据列表中,所有的年龄分布情况 db.student.distinct(“age”, {}) 分页
#隔n个数据查询m个数据 db.hero.find().pretty().limit(m).skip(n)
统计
.count() db. <集合名称> .count({条件}) 两种操作方式 1.查询结果,通过count()统计数据 2.通过count()直接添加条件统计数据
5.Mongodb与python交互
之前学习了爬虫,现在我们把爬取得到的数据存储于Mongodb中
#-*- coding:utf-8 -*- import pymongo import requests from bs4 import BeautifulSoup #建立于MongoClient 的连接 client = pymongo.MongoClient('localhost',27017) #得到数据库 hero = client['hero'] #得到一个数据集合 sheet_tab = hero['sheet_tab'] url = 'http://lol.duowan.com/hero/' req = requests.get(url) soup = BeautifulSoup(req.text,'html.parser') links = soup.find(id="champion_list").find_all('a') for link in links: link = link['href'] requ = requests.get(link) sop = BeautifulSoup(requ.text,'html.parser') data = { 'title' : sop.find('h2',class_="hero-title").get_text(), 'name' : sop.find('h1',class_="hero-name").get_text(), 'tags' : sop.find('div',class_="hero-box ext-attr").find_all('span')[1].get_text(), 'story' : sop.find('div',class_="hero-popup").find_all('p')[0].get_text(), } sheet_tab.insert_one(data) 所以存储于不同的数据库也是基本功。
精选好文:
重磅 !开源一个机器学习/情感分析实战项目(附源码/教程)
分享Django+Linux+Uwsgi+Nginx项目部署文档
python自动化测试技术打造升职加薪利器
110道python面试题
我去面试python岗位了
一幅漫画看透零基础转Python学习路线
工作必备,耗时3天总结踩坑写的超实用前端教程
python爬虫人工智能大数据公众号

转载地址:http://txatv.baihongyu.com/